Important Probability Distributions#
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set_theme()
import numpy as np
import pandas as pd
We will make use of the stats package within the scipy suite of tools for scientific python
import scipy.stats
Overview#
Is this section we provide a brief overview of probability distributions that follows from the previous proabability theory lecture.
What is a Probability Distribution?#
A probability distribution is a mathematical function that defines the likelihood of different outcomes or values of a random variable. Probability distributions are fundamental in probability theory and statistics and useful for for analyzing scientific data and making predictions. We more formally refer to these functions as probability density functions (PDFs) when they are normalized to unity such that the intetral over their domain equals 1.
A brief description of probability distributions, often encountered in practical applications, is presented in the following. The rationale leading to this choice of PDFs is driven either by their specific mathematical properties, and/or in view of their common usage in the modellingi of important physical processes; such features are correspondingly emphasized in the discussion.
Zoology of PDFs in SciPy#
There are many named statistical distributions with useful properties and/or interesting history. For example, in the scipy.stats module we find a large number of 1D continuous random variable distributions:
len(scipy.stats.rv_continuous.__subclasses__())
106
and a smaller number of 1D discrete distributions:
len(scipy.stats.rv_discrete.__subclasses__())
20
and multidimensional continuous distributions:
len(scipy.stats._multivariate.multi_rv_generic.__subclasses__())
16
Some Useful Probabiltiy Distributions#
You will likely never need all or even most of these probability distributions in practical application, but it is useful to know about them. Most have special applications that they were created for, but can also be useful as building blocks of an empirical distribution when you just want something that looks like the data.
1D Continuous Distributions#
It is useful to group the large number of 1D continuous distributions according to their general shape. We will use the function below for a quick visual tour of some PDFs in each group:
def pdf_demo(xlo, xhi, **kwargs):
x = np.linspace(xlo, xhi, 200)
cmap = sns.color_palette().as_hex()
for i, name in enumerate(kwargs):
for j, arglist in enumerate(kwargs[name].split(';')):
args = eval('dict(' + arglist + ')')
y = eval('scipy.stats.' + name)(**args).pdf(x)
plt.plot(x, y, c=cmap[i], ls=('-','--',':')[j], label=name)
plt.xlim(x[0], x[-1])
plt.legend(fontsize='large')
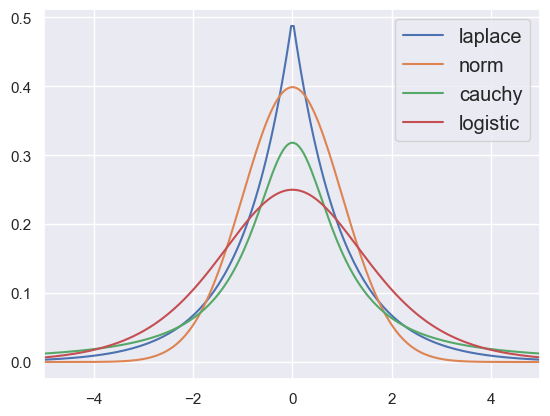
First, the centered symmetric peaked distributions, including the ubiquitous Gaussian (here called “norm”) and Lorentzian (here called “cauchy”). Each of these can be re-centered using the loc (location) parameter and broadened using scale:
pdf_demo(-5, +5, laplace='scale=1', norm='scale=1', cauchy='scale=1', logistic='scale=1')
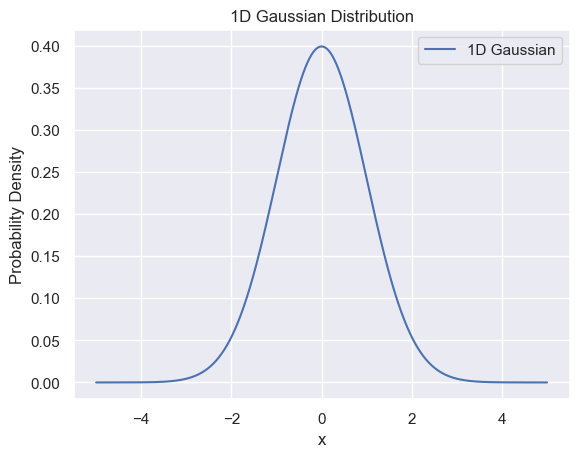
The Gaussian Distribution in 1D and 2D#
The Gaussian distribution is commoning found in scientific applications, for example representing the response function of an observable in an experimental apparatus with finite resolution. It is given by
where
\(\mu\) represents the mean (average) of the distribution.
\(\sigma\) represents the standard deviation of the distribution.
\(x\) is the variable for which you want to calculate the probability density.
# Define parameters
mu = 0 # Mean
sigma = 1 # Standard deviation
# Create data points
x = np.linspace(-5, 5, 1000) # Range of x values
# Calculate the 1D Gaussian function
gaussian = (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
# Plot the Gaussian function
plt.plot(x, gaussian, label='1D Gaussian')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.legend()
plt.title('1D Gaussian Distribution')
plt.grid(True)
plt.show()
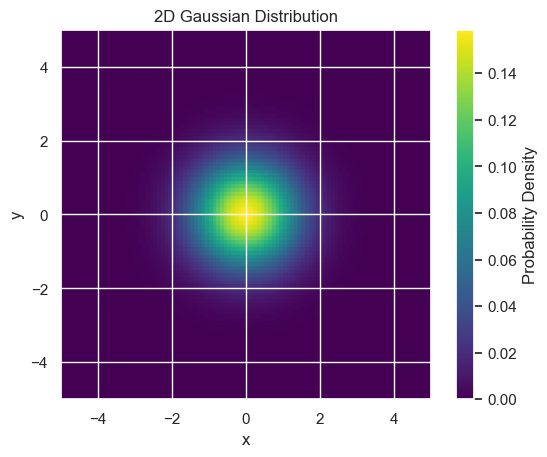
# Define parameters
mu_x = 0 # Mean along x-axis
mu_y = 0 # Mean along y-axis
sigma_x = 1 # Standard deviation along x-axis
sigma_y = 1 # Standard deviation along y-axis
# Create a grid of x and y values
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
X, Y = np.meshgrid(x, y)
# Calculate the 2D Gaussian function
gaussian = (
1 / (2 * np.pi * sigma_x * sigma_y)
) * np.exp(
-((X - mu_x)**2 / (2 * sigma_x**2) + (Y - mu_y)**2 / (2 * sigma_y**2))
)
# Plot the 2D Gaussian function as a heatmap
plt.imshow(gaussian, cmap='viridis', extent=(-5, 5, -5, 5), origin='lower')
plt.colorbar(label='Probability Density')
plt.xlabel('x')
plt.ylabel('y')
plt.title('2D Gaussian Distribution')
plt.show()
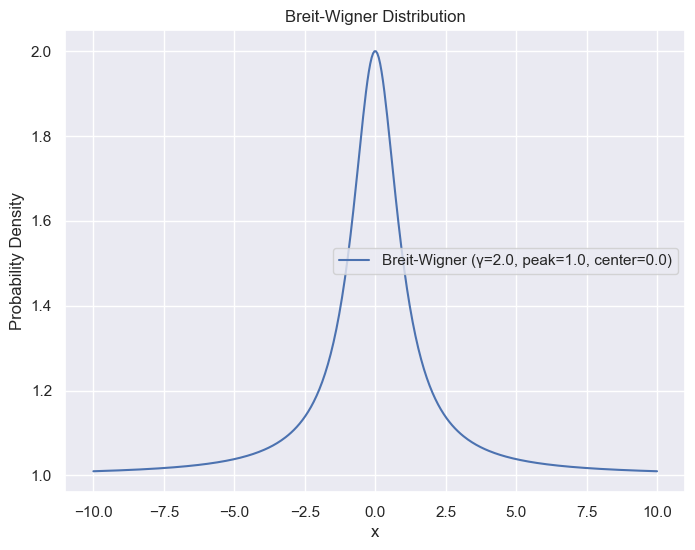
The Breit-Wigner distribution#
The Breit-Wigner distribution is a probability distribution often used in physics to describe resonances or the shape of spectral lines. It is also known by several other names and variations, depending on the context and field of study. The Breit-Wigner is also called Lorentzian by physicists, and in mathematics circles it is often referred to as the Cauchy distribution.
In the context of relativistic kinematics, the Breit-Wigner function provides a good description of a resonant process (for example the invariant mass of decay products from a resonant intermediate state); for a resonance, the parameters x0 and Γ are referred to as its mass and its natural width, respectively.
whose parameters are the most probable value \(x_0\) (which specifies the peak of the distribution), and the FWHM \(\Gamma\).
With some representative parameters, it look like this:
# Define the Breit-Wigner distribution function
def breit_wigner(x, gamma, peak, center):
return (gamma / 2) / ((x - center)**2 + (gamma / 2)**2) + peak
# Parameters for the distribution
gamma = 2.0 # Width parameter (half-width at half-maximum)
peak = 1.0 # Peak height
center = 0.0 # Center position
# Generate x values
x = np.linspace(-10, 10, 400)
# Calculate the corresponding y values using the Breit-Wigner function
y = breit_wigner(x, gamma, peak, center)
# Create a plot
plt.figure(figsize=(8, 6))
plt.plot(x, y, label=f'Breit-Wigner (γ={gamma}, peak={peak}, center={center})')
plt.title('Breit-Wigner Distribution')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.legend()
plt.grid(True)
plt.show()
The Breit-Wigner probability distribution has a peculiar feature, as a consequence of its long-range tails: the empirical average and empirical RMS are ill-defined (their variance increase with the size of the samples), and cannot be used as estimators of the Breit-Wigner parameters. The truncated mean and interquartile range, which are obtained by removing events in the low and high ends of the sample, are safer estimators of the Breit-Wigner parameters
There are also some more specialized asymmetric “bump” distributions that are particularly useful for modeling histograms of reconstructed particle masses (even more specialized is the Cruijff function used here):
pdf_demo(0, 10, crystalball='beta=1,m=3,loc=6;beta=10,m=3,loc=6', argus='chi=0.5,loc=5,scale=2;chi=1.5,loc=5,scale=2')
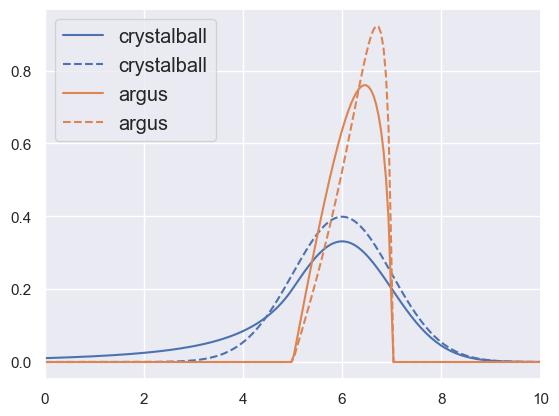
The Crystal Ball distribution#
The Crystal Ball function is named after the Crystal Ball Collaboration. The Crystal Ball was a hermetic particle detector used initially with the SPEAR particle accelerator at the Stanford Linear Accelerator Center beginning in 1979. It was designed to detect neutral particles and was used to discover the ηc meson.
The Crystal Ball function is a probability density function commonly used to model various lossy processes in high-energy physics. It consists of a Gaussian core portion and a power-law low-end tail, below a certain threshold. The function itself is shown below
Both the function and its first derivative are both continuous.
Crystall Ball functions were used to model the Higgs boson di-photon signal shape in the \(H\to\gamma\gamma\) decay channel for the 2012 Higgs boson discovery by the ATLAS and CMS Collaborations.
Next, the “one-sided” distributions that are only defined for \(x \ge 0\). Most of these smoothly transition from peaking at the origin to peaking at \(x > 0\) as some parameter is varied. These are useful building blocks for quantities that must be positive, e.g., errors or densities.
pdf_demo(-0.5, 5, gamma='a=1;a=2', lognorm='s=0.5;s=1.5', chi2='df=2;df=3')
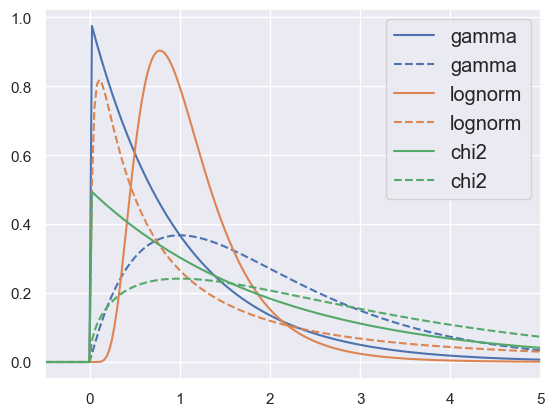
The Exponential distribution#
The exponential distribution is a special case of the Gamma distribution with the shape parameter \(a=1\), although the exponential distribution is only supported for \(x \ge 0\). The exponential distribution is one of the widely used continuous distributions. It is often used to model the time elapsed between events, such as the decay of unstable nuclei. A common application of this exponential distribution is the description of phenomena occuring independently at a constant rate, such as decay lengths and lifetimes.
It is given by:
where \(\lambda\) is the rate parameter.
In view of the self-similar feature of the exponential function:
the exponential distribution is sometimes said to be memoryless.
The Chi-squared distribution#
The chi2 distribution (\(\chi^2\)) is especially useful for parameter fitting, goodness-of-fit measures, and confidence interval calculations. It is given by:
where \(x\) is the random variable, \(n\) is the number of degrees of freedom, and \(\Gamma\) is the Gamma function (in fact, the \(\chi^2\) distribution can be considered to be a special case of the \(\Gamma\) function).
The name “degrees-of-freedom” refers to the expected behaviour of a least-square fit involving the \(\chi^2\) test statistic,
where \(n_d\) data points are used to estimate a set of \(n_p\) parameters \(\vec{\alpha}\); the corresponding number of degrees of freedom is \(n_d\) − \(n_p\).
For a well-behaved fit where the deviation of the measured points from the model follows Gaussian distributions with variances \(\sigma^2_i\), the \(\chi^2\) value should follow a \(\chi^2\) distribution. The comparison of an observed \(\chi^2\) value with its expectation, is an example of goodness-of-fit test (Pearson’s test).
Here are two handy utilities that you will likely need at some point, expecially when we talk about confidence intervals (using the CDF and inverse-CDF functions):
def nsigmas_to_CL(nsigmas=1., D=1):
return scipy.stats.chi2.cdf(x=nsigmas ** 2, df=D)
def CL_to_nsigmas(CL=0.95, D=1):
return np.sqrt(scipy.stats.chi2.ppf(q=CL, df=D))
For example, a “1-sigma” error bar contains ~68% of a Gaussian distribution in 1D, but a 2D “1-sigma” contour only contains ~39%:
nsigmas_to_CL(nsigmas=1, D=[1, 2])
array([0.68268949, 0.39346934])
To find the number of sigmas required to enclose a specific integrated probability (aka “confidence level (CL)”) in D dimensions:
CL_to_nsigmas(CL=0.95, D=[1, 2])
array([1.95996398, 2.44774683])
Another useful group are the “bounded” distributions, especially the versatile two-parameter beta distribution:
pdf_demo(-0.1, 1.1, beta='a=.7,b=.7;a=1.5,b=1.5;a=.9,b=1.5', cosine='loc=0.5,scale=0.159',
uniform='scale=1')
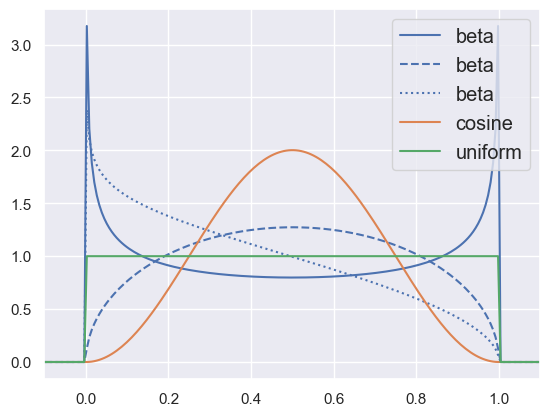
All of the 1D continuous distributions share the same API (via a common base class), and allow you to perform useful operations including:
Evaluate the PDF, log(PDF), CDF or log(CDF).
Generate random values from the distribution.
Calculate expectation values of moment functions or even arbitrary functions.
The API also allows you to estimate the values of distribution parameters that best describe some data, but we will soon see better approaches to this “regression” problem.
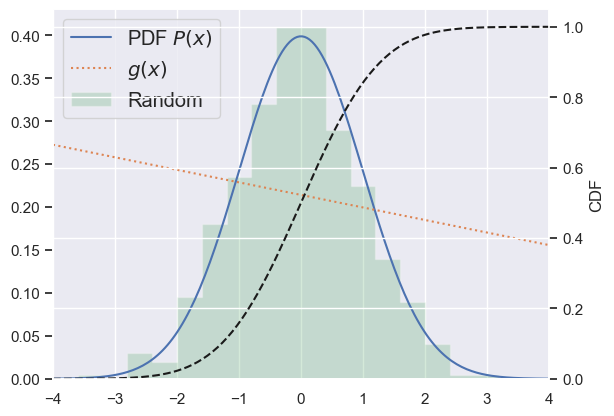
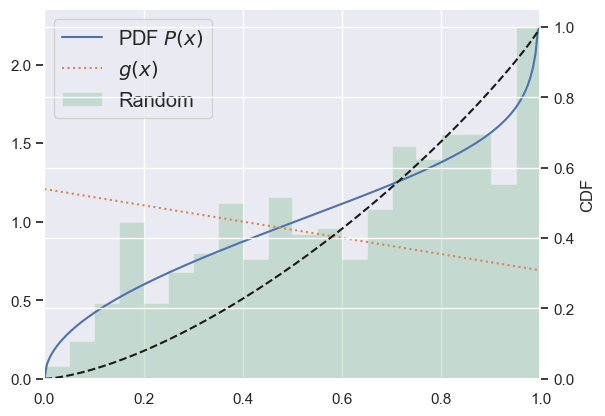
def rv_continuous_demo(xlo, xhi, dist, seed=123, n=500):
x = np.linspace(xlo, xhi, 200)
P = dist.pdf(x)
plt.plot(x, P, ls='-', label='PDF $P(x)$')
g = lambda x: (0.7 - 0.3 * (x - xlo) / (xhi - xlo)) * np.percentile(P, 95)
plt.plot(x, g(x), ':', label='$g(x)$')
print('<g> =', dist.expect(g))
gen = np.random.RandomState(seed=seed)
data = dist.rvs(size=n, random_state=gen)
plt.hist(data, range=(xlo, xhi), bins=20, histtype='stepfilled',
alpha=0.25, density=True, stacked = True, label='Random')
plt.ylim(0, None)
plt.grid(axis='y')
plt.legend(loc='upper left', fontsize='large')
rhs = plt.twinx()
rhs.set_ylabel('CDF')
rhs.set_ylim(0., 1.05)
rhs.grid('off')
rhs.plot(x, dist.cdf(x), 'k--')
plt.xlim(xlo, xhi)
rv_continuous_demo(-4, +4, scipy.stats.norm())
<g> = 0.21420671411482053
rv_continuous_demo(0, 1, scipy.stats.beta(a=1.5,b=0.9))
<g> = 0.8840573776020221
1D Discrete Distributions#
Finally, there are some essential discrete random variable distributions, where the PDF is replaced with what is called in probabilty and statistics a probability mass function (PMF):
def pmf_demo(klo, khi, **kwargs):
k = np.arange(klo, khi + 1)
cmap = sns.color_palette().as_hex()
histopts = {'bins': khi-klo+1, 'range': (klo-0.5,khi+0.5), 'histtype': 'step', 'lw': 2}
for i, name in enumerate(kwargs):
for j, arglist in enumerate(kwargs[name].split(';')):
args = eval('dict(' + arglist + ')')
y = eval('scipy.stats.' + name)(**args).pmf(k)
plt.hist(k, weights=y, color=cmap[i], linestyle=('-','--',':')[j], label=name, **histopts)
plt.legend(fontsize='large')
The PMF is also known as the discrete probability density function (dPDF). Lets roll with the PMF name even though I do not really like it since it has nothing to do with physical mass. However, thinking of probability as mass helps to avoid mistakes since the physical mass is conserved as is the total probability for all hypothetical outcomes.
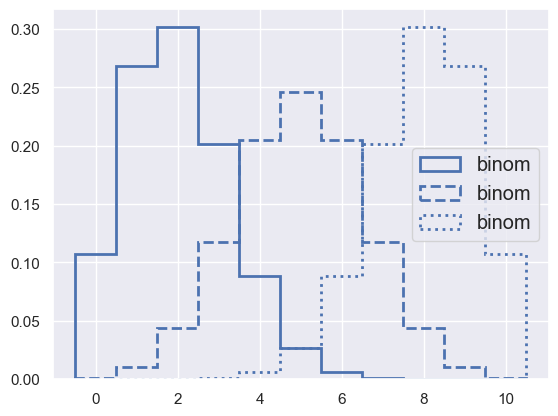
The Binomial Distribution#
Consider a scenario with two possible outcomes: “success” or “failure”, with a fixed probability \(p\) of “success” being realized (this is also called a Bernouilli trial). If \(n\) trials are performed, \(0 ≤ k ≤ n\) may actually result in “success”; it is assumed that the sequence of trials is irrelevant, and only the number of “success” \(k\) is considered of interest. The integer number \(k\) follows the so-called binomial distribution \(P(k; n, p)\):
where \(\binom{n}{k}\) is the binomial coefficient, which can be calculated as
The binomial distribution is related to the beta distribution previously shown, and describes the statistics of ratios of counting measurements (efficiency, purity, completeness, …):
pmf_demo(0, 10, binom='n=10,p=0.2;n=10,p=0.5;n=10,p=0.8')
The Poisson Distribution#
In the \(n → ∞\), \(~p → 0\) limit (with \(λ = np\) finite and non-zero) for the Binomial distribution, the random variable \(k\) follows the Poisson distribution \(P(k; \lambda)\),
where \(\lambda\) is the rate parameter defining the average rate at which events occur.
The Poisson distribution is sometimes called the “law of rare events” in view of the \(p → 0\) limit. It is a useful model for describing the statistics of event-counting rates in (uncorrelated) counting measurements (which are ubiquitous in astronomy and particle physics)
pmf_demo(0, 10, poisson='mu=2;mu=3;mu=4')
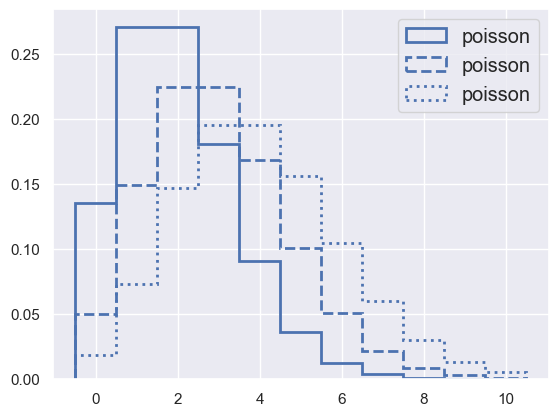
Poisson distribution is used to model the number of events occuring in the future, In comparison to the previously described Exponential and Gamma distributions, the Exponential distribution is used to predict the wait time until the very first event, and Gamma distribution is used to predict the wait time until the \(\alpha\)-th event.
Central Limit Theorem#
The Central Limit Theorem (CLT) is a fundamental concept in statistics that describes the behavior of the sampling distribution of the sample mean (or other sample statistics) of a random sample from any population, regardless of its underlying distribution.
The Central Limit Theorem can be stated as follows:
When independent and identically distributed random variables are sampled from a population, the distribution of the sample means approaches a normal distribution as the sample size increases, regardless of the shape of the original population distribution.
Another slightly less precise but more concise statement of the CLT is:
The mean (or sum) of samples drawn from any distribution tends toward a Gaussian distribution.
A few key points about the CLT:
Independence: The random variables in the sample must be independent, meaning that the outcome of one observation does not affect the outcome of another.
Identical Distribution: Each random variable in the sample must be drawn from the same probability distribution.
Sample Size: As the sample size increases, the sampling distribution of the sample mean becomes increasingly closer to a normal distribution, with the mean of the sampling distribution equal to the population mean and a standard deviation (standard error) that depends on the population standard deviation and the square root of the sample size.
The CLT is a crucial theorem in probability theory and statistics and has wide-ranging applications in data analysis. It allows us to make statistical inferences about a population based on the distribution of sample means, even when we don’t know the exact nature of the population distribution. It provides the theoretical foundation for hypothesis testing, confidence intervals, and many other statistical techniques. It is also often used when dealing with large datasets, common in particle physics and astrophysics, as it allows us to assume that the distribution of sample means is approximately normal, simplifying many statistical analyses.
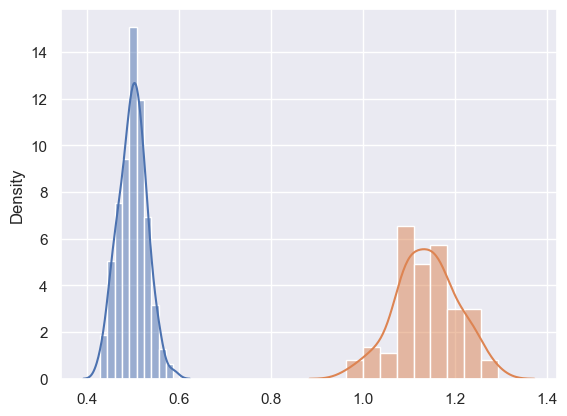
The following exercise provides a simple numerical demonstration of the CLT:
EXERCISE: Fill in the function below to generate nsample samples of size size from an arbitrary 1D continuous distribution, and then display an sns.distplot of the mean values of each generated sample:
def central_limit_demo(dist, nsample, size, seed=123):
gen = np.random.RandomState(seed=seed)
...
Test your function using:
central_limit_demo(scipy.stats.uniform(scale=1), nsample=100, size=100)
central_limit_demo(scipy.stats.lognorm(s=0.5), nsample=100, size=100)
def central_limit_demo(dist, nsample, size, seed=123):
gen = np.random.RandomState(seed=seed)
means = []
for i in range(nsample):
data = dist.rvs(size=size, random_state=gen)
means.append(np.mean(data))
sns.histplot(means, kde=True, stat="density", kde_kws=dict(cut=3))
central_limit_demo(scipy.stats.uniform(scale=1), nsample=100, size=100)
central_limit_demo(scipy.stats.lognorm(s=0.5), nsample=100, size=100)
Here is a nicer interactive demonstration you can experiment with.
Not surprisingly, any measurement subject to multiple sources of fluctuations is likely to follow a distribution that can be approximated with a Gaussian distribution to a good approximation, regardless of the specific details of the processes at play.
The Gaussian is also encountered as the limiting distribution for the Binomial and and Poisson ones, in the large \(n\) and large \(\lambda\) limits, respectively:
Note that, when using a Gaussian as approximation, an appropriate continuity correction needs to be taken into account: the range of the Gaussian extends to negative values, while Binomial and Poisson are only defined in the positive range.
The Galton Board is a device invented by Sir Francis Galton in 1894 to demonstrate the CLT, in particular that with sufficient sample size the binomial distribution approximates a normal distribution.
The Galton board we have in class consists of a vertical board with interleaved rows of pegs. 6000 Beads are dropped from the top and, when the device is level, bounce either left or right equally as they hit the pegs. Eventually they are collected into bins at the bottom, where the height of bead columns accumulated in the bins approximate a normal distribution. Overlaying Pascal’s triangle onto the pins shows the number of different paths that can be taken to get to each bin.
For a more powerful statistical toolbox than scipy.stats, try the python statsmodels package. Going beyond python, the R language is designed specifically for “statistical computing” (and integrated in jupyter), and RooFit is a “a toolkit for modeling the expected distribution of events in a physics analysis” integrated into the ROOT framework.
We will be soon be talking more about the general problem of “fitting” the parameters of a distribution to match some data.
Acknowledgments#
Initial version: Mark Neubauer
© Copyright 2025