Monte Carlo and Sampling Methods#
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set_theme()
from numpy import random
import numpy as np
import pandas as pd
from tqdm import tqdm, trange # prints a nice loading bar for the notebook
import timeit
from numba import jit
import copy
from ipywidgets import interact, interactive, fixed, interact_manual
import ipywidgets as widgets
import scipy.stats as stats
import warnings
warnings.filterwarnings('ignore')
Introduction#
Monte Carlo (MC) integration and other sampling techniques are important tools for computing complex intgerals that arising in many areas of science. In this lecture, we will study Monte Carlo integration methods.
Monte Carlo Integration#
Numerical integration uses the rectangle approximation to find the area under a curve. The analytical notation we are used to seeing for a definite integral
can be expressed as a numerical approximation that adds up \(n\) rectangles under the curve \(f(x)\). The more rectangles used to calculate the area, the better the approximation becomes.
Monte Carlo Integration is a process of solving integrals having numerous values to integrate upon. The Monte Carlo process uses the theory of large numbers and random sampling to approximate values that are very close to the actual solution of the integral.
Monte Carlo Integration improves above the integration approach by randomly picking which rectangles to add up next and approximating \(F\) as \(\langle F^N \rangle\):
where \(N\) is the number of times a new value \(X_i\) is chosen from a probability distribution for range \(a\) to \(b\). Therefore,
The question becomes, what is the best way to choose \(X_i\) to match the real system? The goal is to get the best approximation as quickly as possible.
EXAMPLE: Lets appoximate the definite integral using the Monte Carlo integration method:
# limits of integration
a = 0
b = np.pi # gets the value of pi
N = 1000
# array of zeros of length N
ar = np.zeros(N)
# iterating over each Value of ar and filling
# it with a random value between the limits a
# and b
for i in range (len(ar)):
ar[i] = random.uniform(a,b)
# variable to store sum of the functions of
# different values of x
integral = 0.0
# function to calculate the sin of a particular
# value of x
def f(x):
return np.sin(x)
# iterates and sums up values of different functions
# of x
for i in ar:
integral += f(i)
# we get the answer by the formula derived adobe
ans = (b-a)/float(N)*integral
# prints the solution
print ("The value calculated by monte carlo integration is {}.".format(ans))
The value calculated by monte carlo integration is 1.9716824118014005.
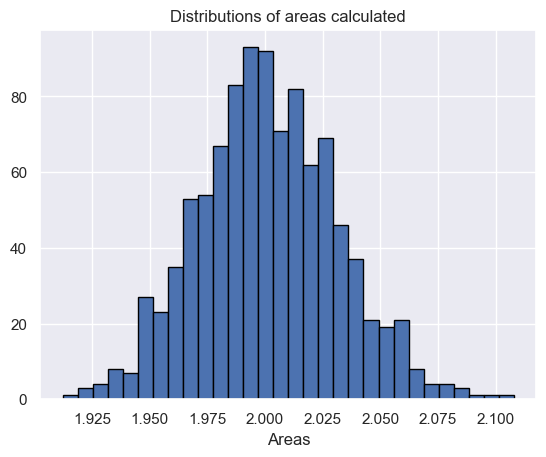
The value obtained is very close to the actual answer of the integral which is 2.0.
Now if we want to visualize the integration using a histogram, we can do so by using the matplotlib library. Again we import the modules, define the limits of integration and write the sin function for calculating the sin value for a particular value of x. Next, we take an array that has variables representing every bin of the histogram. Then we iterate through N values and repeat the same process of creating a zeros array, filling it with random x values, creating an integral variable adding up all the function values, and getting the answer N times, each answer representing a bin of the histogram.
# limits of integration
a = 0
b = np.pi # gets the value of pi
N = 1000
# function to calculate the sin of a particular
# value of x
def f(x):
return np.sin(x)
# list to store all the values for plotting
plt_vals = []
# we iterate through all the values to generate
# multiple results and show whose intensity is
# the most.
for i in range(N):
#array of zeros of length N
ar = np.zeros(N)
# iterating over each Value of ar and filling it
# with a random value between the limits a and b
for i in range (len(ar)):
ar[i] = random.uniform(a,b)
# variable to store sum of the functions of different
# values of x
integral = 0.0
# iterates and sums up values of different functions
# of x
for i in ar:
integral += f(i)
# we get the answer by the formula derived adobe
ans = (b-a)/float(N)*integral
# appends the solution to a list for plotting the graph
plt_vals.append(ans)
# details of the plot to be generated
# sets the title of the plot
plt.title("Distributions of areas calculated")
# 3 parameters (array on which histogram needs
plt.hist (plt_vals, bins=30, ec="black")
# to be made, bins, separators colour between the
# beams)
# sets the label of the x-axis of the plot
plt.xlabel("Areas")
plt.show() # shows the plot
EXAMPLE: Lets appoximate the definite integral
# limits of integration
a = 0
b = 1
N = 1000
# array of zeros of length N
ar = np.zeros(N)
# iterating over each Value of ar and filling
# it with a random value between the limits a
# and b
for i in range(len(ar)):
ar[i] = random.uniform(a, b)
# variable to store sum of the functions of
# different values of x
integral = 0.0
# function to calculate the sin of a particular
# value of x
def f(x):
return x**2
# iterates and sums up values of different
# functions of x
for i in ar:
integral += f(i)
# we get the answer by the formula derived adobe
ans = (b-a)/float(N)*integral
# prints the solution
print("The value calculated by monte carlo integration is {}.".format(ans))
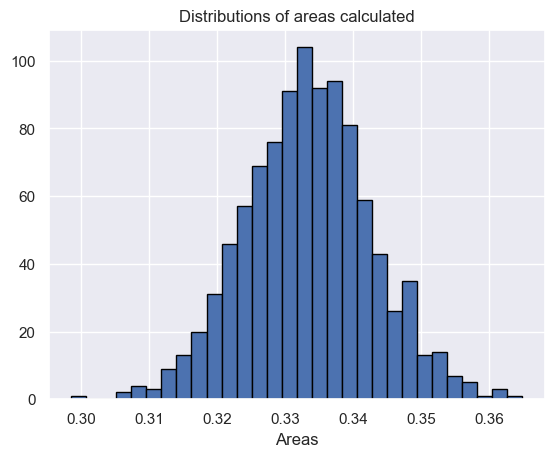
The value calculated by monte carlo integration is 0.3166840507684501.
And then visualize:
# limits of integration
a = 0
b = 1
N = 1000
# function to calculate x^2 of a particular value
# of x
def f(x):
return x**2
# list to store all the values for plotting
plt_vals = []
# we iterate through all the values to generate
# multiple results and show whose intensity is
# the most.
for i in range(N):
# array of zeros of length N
ar = np.zeros(N)
# iterating over each Value of ar and filling
# it with a random value between the limits a
# and b
for i in range (len(ar)):
ar[i] = random.uniform(a,b)
# variable to store sum of the functions of
# different values of x
integral = 0.0
# iterates and sums up values of different functions
# of x
for i in ar:
integral += f(i)
# we get the answer by the formula derived adobe
ans = (b-a)/float(N)*integral
# appends the solution to a list for plotting the
# graph
plt_vals.append(ans)
# details of the plot to be generated
# sets the title of the plot
plt.title("Distributions of areas calculated")
# 3 parameters (array on which histogram needs
# to be made, bins, separators colour between
# the beams)
plt.hist (plt_vals, bins=30, ec="black")
# sets the label of the x-axis of the plot
plt.xlabel("Areas")
plt.show() # shows the plot
Multidimensional Monte Carlo integration and variance scaling#
We can estimate the Monte Carlo variance of the approximation as
Also, from the Central Limit Theorem,
The convergence of Monte Carlo integration is \(O(\sqrt{N})\) and independent of the dimensionality. Hence Monte Carlo integration generally beats numerical integration for moderate- and high-dimensional integration since numerical integration (quadrature) converges as \(O(N^d)\). Even for low dimensional problems, Monte Carlo integration may have an advantage when the volume to be integrated is concentrated in a very small region and we can use information from the distribution to draw samples more often in the region of importance.
EXAMPLE: 3-D Integration
Uniform 3-D random variable:
Basic 3-D estimator:
This generalizes to abitrary N-dimensional PDFs
Variance and Bias in Monte Carlo integration#
We are often interested in knowing how many iterations it takes for Monte Carlo integration to “converge” and the accuracy of the calculation. To do this, we would like some estimate of the variance and to ensure it is unbiased. It is useful to inspect such plots. One simple way to get confidence intervals for the plot of Monte Carlo estimate against number of iterations is simply to do many such simulations.
EXAMPLE: Using Monte Carlo methods, estimate the integral of the function
def f(x):
return x * np.cos(71*x) + np.sin(13*x)
x = np.linspace(0, 1, 100)
plt.plot(x, f(x))
pass
Single Monte Carlo estimate#
n = 100
x = f(np.random.random(n))
y = 1.0/n * np.sum(x)
print(y)
0.03002375020906809
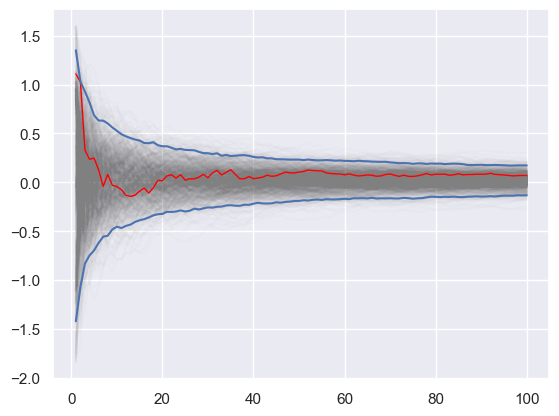
Using multiple independent sequences to monitor convergence#
We vary the sample size from 1 to 100 and calculate the value of \(y=\sum x / n\) for 1000 replicates. We then plot the 2.5th and 97.5th percentile of the 1000 values of \(y\) to see how the variation in \(y\) changes with sample size. The blue lines indicate the 2.5th and 97.5th percentiles, and the red line a sample path.
n = 100
reps = 1000
x = f(np.random.random((n, reps)))
y = 1/np.arange(1, n+1)[:, None] * np.cumsum(x, axis=0)
upper, lower = np.percentile(y, [2.5, 97.5], axis=1)
plt.plot(np.arange(1, n+1), y, c='grey', alpha=0.02)
plt.plot(np.arange(1, n+1), y[:, 0], c='red', linewidth=1);
plt.plot(np.arange(1, n+1), upper, 'b', np.arange(1, n+1), lower, 'b')
pass
Proof that Monte Carlo Estimator is Unbiased#
It is straightforward to prove that the expectation value of the Monte Carlo estimator is the desired integral (i.e. it is unbiased).
First recall some properties of the expectation value \(E\):
Then
Change of Variables#
The Cauchy distribution is given by
Suppose we want to integrate the tail probability \(P(X>3)\) using Monte Carlo. One way to do this is to draw many samples form a Cauchy distribution, and count how many of them are greater than 3, but this is extremely inefficient.
Only 10% of samples will be used
h_true = 1 - stats.cauchy().cdf(3)
print(h_true)
0.10241638234956674
n = 100
x = stats.cauchy().rvs(n)
h_mc = 1.0/n * np.sum(x > 3)
h_mc, np.abs(h_mc - h_true)/h_true
(np.float64(0.06), np.float64(0.4141562255615659))
A change of variables lets us use 100% of draws#
We are trying to estimate the quantity
Using the substitution \(y=3/x\) (and a little algebra), we get
Hence, a much more efficient MC estimator is
where \(y_i \sim \square(0,1)\)
y = stats.uniform().rvs(n)
h_cv = 1.0/n * np.sum(3.0/(np.pi * (9 + y**2)))
h_cv, np.abs(h_cv - h_true)/h_true
(np.float64(0.10251647133224383), np.float64(0.0009772751231874972))
Monte Carlo Swindles#
Apart from change of variables, there are several general techniques for variance reduction, sometimes known as Monte Carlo “swindles” since these methods improve the accuracy and convergence rate of Monte Carlo integration without increasing the number of Monte Carlo samples. Some Monte Carlo swindles are:
importance sampling
stratified sampling
control variates
antithetic variates
conditioning swindles including Rao-Blackwellization and independent variance decomposition
Most of these techniques are not particularly computational in nature, so we will not cover them in the course. I expect you will learn them elsewhere. We will illustrate importance sampling and antithetic variables here as examples.
Antithetic variables#
The idea behind antithetic variables is to choose two sets of random numbers that are negatively correlated, then take their average, so that the total variance of the estimator is smaller than it would be with two sets of independent and identically distributed (IID) random variables.
def f(x):
return x * np.cos(71*x) + np.sin(13*x)
from sympy import sin, cos, symbols, integrate
x = symbols('x')
sol = integrate(x * cos(71*x) + sin(13*x), (x, 0,1)).evalf(16)
print(sol)
0.02025493910239406
Using just vanilla Monte Carlo:
n = 10000
u = np.random.random(n)
x = f(u)
y = 1.0/n * np.sum(x)
y, abs(y-sol)/sol
(np.float64(0.019486298255428573), 0.03794831685643693)
Using antithetic variables for the first half of \(u\) supplemented with \(1-u\):
u = np.r_[u[:n//2], 1-u[:n//2]]
x = f(u)
y = 1.0/n * np.sum(x)
y, abs(y-sol)/sol
(np.float64(0.012381203124551024), 0.3887316539456980)
This works because the random draws are now negatively correlated, and hence the sum of the variances will be less than in the IID case, while the expectation is unchanged.
Importance Sampling#
Ordinary Monte Carlo sampling evaluates
Using another distribution \(h(x)\) which is the so-called “importance function”, we can rewrite the above expression as an expectation with respect to \(h\)
giving us the new estimator
where \(x_i \sim f\) is a draw from the density \(h\).
This is helpful if the distribution \(h\) has a similar shape as the function \(f(x)\) that we are integrating over, since we will draw more samples from places where the integrand makes a larger or more “important” contribution. This is very dependent on a good choice for the importance function \(h\).
Two simple choices for \(h\) are scaling
and translation
In these cases, the parameter a is typically chosen using some adaptive algorithm, giving rise to adaptive importance sampling. Alternatively, a different distribution can be chosen as shown in the example below.
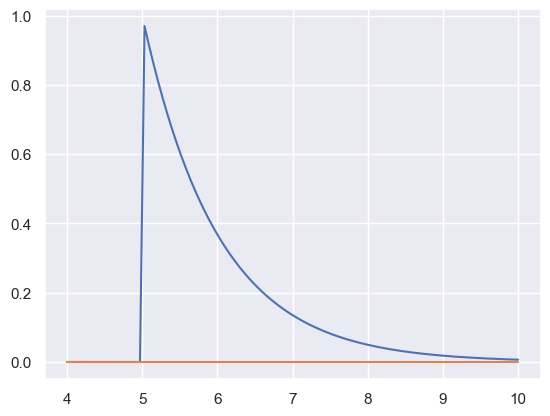
EXAMPLE: Suppose we want to estimate the tail probability of \(\square (0,1)\) for \(P(X>5)\).
Regular MC integration using samples from \(\square (0,1)\) is hopeless since nearly all samples will be rejected. However, we can use the exponential density truncated at 5 as the importance function and use importance sampling.
x = np.linspace(4, 10, 100)
plt.plot(x, stats.expon(5).pdf(x))
plt.plot(x, stats.norm().pdf(x))
pass
Expected answer#
We expect about 3 draws out of 10,000,000 from \(\square (0,1)\) to have a value greater than 5. Hence simply sampling from \(\square (0,1)\) is hopelessly inefficient for Monte Carlo integration.
%precision 10
'%.10f'
h_true = 1 - stats.norm().cdf(5)
h_true
0.0000002867
Using direct Monte Carlo integration#
n = 10000
y = stats.norm().rvs(n)
h_mc = 1.0/n * np.sum(y > 5)
# estimate and relative error
h_mc, np.abs(h_mc - h_true)/h_true
(0.0000000000, 1.0000000000)
Using importance sampling#
n = 10000
y = stats.expon(loc=5).rvs(n)
h_is = 1.0/n * np.sum(stats.norm().pdf(y)/stats.expon(loc=5).pdf(y))
# estimate and relative error
h_is, np.abs(h_is- h_true)/h_true
(0.0000002846, 0.0070936205)
Vegas Method#
The VEGAS algorithm, due to G. Peter Lepage, is a method for reducing error in Monte Carlo simulations by using a known or approximate probability distribution function to concentrate the search in those areas of the integrand that make the greatest contribution to the final integral.
The VEGAS algorithm is based on importance sampling. It samples points from the probability distribution described by the function \(|f|\) so that the points are concentrated in the regions that make the largest contribution to the integral
EXAMPLE: 4-D Monte Carlo integration with Vegas
Here we illustrate the use of vegas by estimating the following integral:
First we define the integrand \(f(x)\) where \(x[d]\) specifies a point in the 4-dimensional space.
We then create an integrator integ which is an integration operator that can be applied to any 4-dimensional function. It is where we specify the integration volume.
Finally we apply integ to our integrand \(f(x)\), telling the integrator to estimate the integral using nitn=10 iterations of the vegas algorithm, each of which uses no more than neval=1000 evaluations of the integrand. Each iteration produces an independent estimate of the integral.
The final estimate is the weighted average of the results from all 10 iterations, and is returned by integ(f ...). The call result.summary() returns a summary of results from each iteration.
#%pip install vegas
import vegas
def f(x):
dx2 = 0
for d in range(4):
dx2 += (x[d] - 0.5) ** 2
return np.exp(-dx2 * 100.) * 1013.2118364296088
# seed the random number generator so results reproducible
np.random.seed((1, 2, 3))
# assign integration volume to integrator
integ = vegas.Integrator([[-1., 1.], [0., 1.], [0., 1.], [0., 1.]])
# adapt to the integrand; discard results
integ(f, nitn=5, neval=1000)
# do the final integral
result = integ(f, nitn=10, neval=1000)
print(result.summary())
print('result = %s Q = %.2f' % (result, result.Q))
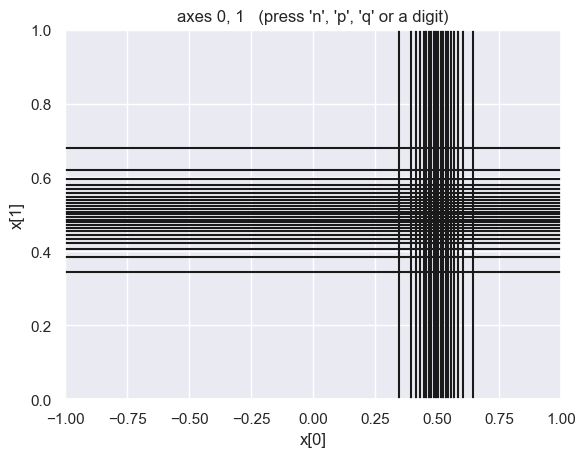
integ.map.show_grid(20)
itn integral wgt average chi2/dof Q
-------------------------------------------------------
1 1.019(28) 1.019(28) 0.00 1.00
2 0.968(21) 0.987(17) 2.10 0.15
3 0.969(16) 0.978(12) 1.35 0.26
4 1.012(14) 0.9917(90) 2.06 0.10
5 1.004(13) 0.9957(73) 1.69 0.15
6 1.008(13) 0.9989(63) 1.50 0.19
7 0.990(11) 0.9965(54) 1.34 0.23
8 0.994(12) 0.9960(49) 1.16 0.32
9 0.987(11) 0.9945(45) 1.09 0.37
10 0.984(11) 0.9930(42) 1.05 0.40
result = 0.9930(42) Q = 0.40
Acknowledgments#
Initial version: Mark Neubauer
From APS DSECOP materials and https://people.duke.edu/~ccc14/sta-663-2016/15C_MonteCarloIntegration.html
© Copyright 2025