Optimization#
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set_theme()
import numpy as np
import pandas as pd
from scipy.optimize import minimize
import scipy.stats
import time
import warnings
warnings.filterwarnings('ignore')
Overview#
Optimization solves the following problem: given a scalar-valued function \(f(\mathbf{x})\) defined in the multidimensional space of \(\mathbf{x}\), find the value \(\mathbf{x}=\mathbf{x}^\ast\) where \(f(\mathbf{x})\) is minimized, or, in more formal language:
This statement of the problem is more general that it first appears, since:
Minimizing \(-f\) is equivalent to maximizing \(f\).
A vector-valued function can also be optimized by defining a suitable norm, \(f = |\vec{f}|\).
Constraints on the allowed values of \(\mathbf{x}\) can be encoded in \(f\) by having it return \(\infty\) in illegal regions.
This is conceptually a straightforward problem, but efficient numerical methods are challenging, especially in high dimensions.
The simplest method is an exhaustive grid search. In 1D, this boils down to making a plot and reading off the lowest value. For example (note the useful np.argmin):
def f(x):
return x ** 2 - 10 * np.exp(-10000 * (x - np.pi) ** 2)
x = np.linspace(-5, +5, 101)
plt.plot(x, f(x), '.')
print('min f(x) at x =', x[np.argmin(f(x))])
min f(x) at x = 0.0
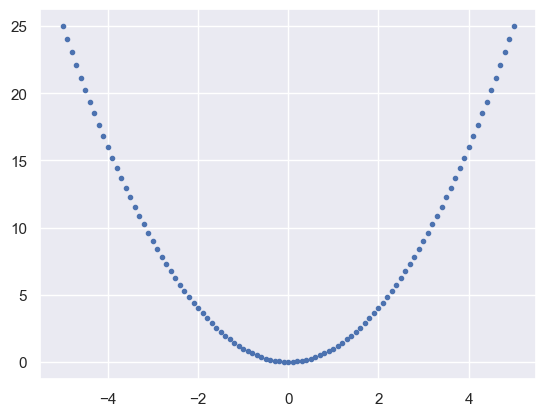
EXERCISE: Study the example above and explain why it fails to find the true minimum of \(f(x)\). Make a different plot that does find the true minimum.
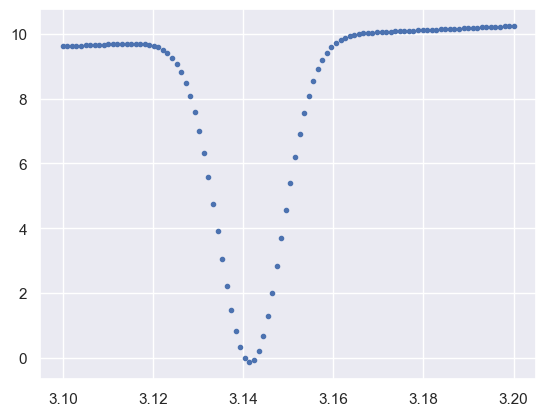
A search using a grid with spacing \(\Delta x\) can completely miss features narrower than \(\Delta x\), so is only reliable when you have some prior knowledge that your \(f(x)\) does not have features narrower than some limit.
x = np.linspace(3.1, 3.2, 100)
plt.plot(x, f(x), '.')
plt.show()
The main computational cost of optimization is usually the evaluation of \(f\), so an important metric for any optimizer is the number of times it evaluates \(f\).
In \(D\) dimensions, a grid search requires \(f\) to be evaluated at \(n^D\) different locations, which becomes prohibitive for large \(D\). Fortunately, there are much better methods when \(f\) satisfies two conditions:
It is reasonably smooth, so that local derivatives reliably point “downhill”.
It has a single global minimum.
The general approach of these methods is to simulate a ball moving downhill until it can go no further.
The first condition allows us to calculate the gradient \(\nabla f(\mathbf{x})\) at the ball’s current location, \(\mathbf{x}_n\), and then move in the downhill direction:
This gradient descent method uses a parameter \(\eta\) to control the size of each step: the ball might overshoot if this is too large, but too small values make unnecessary evaluations. In machine learning contexts, \(\eta\) is often referred to as the learning rate. There are different strategies for adjusting \(\eta\) on the fly, but no universal best compromise between robustness and efficiency.
The second condition is necessary to avoid getting trapped in the false minimum at \(x=0\) in the example above. We often cannot guarantee the second condition but all is not lost: the first condition still allows us to reliably find a local minimum, but we can never know if it is also the global minimum. A practical workaround is to simulate many balls starting from different locations and hope that at least one of them falls into the global minimum.
Convex functions are special since they are guaranteed to meet the second condition. We have already seen that the KL divergence is convex and discussed Jensen’s inequality which applies to convex functions. Convex functions are extremely important in optimization but rare in the wild: unless you know that your function has a single global minimum, you should generally assume that it has many local minima, especially in many dimensions.
Derivatives#
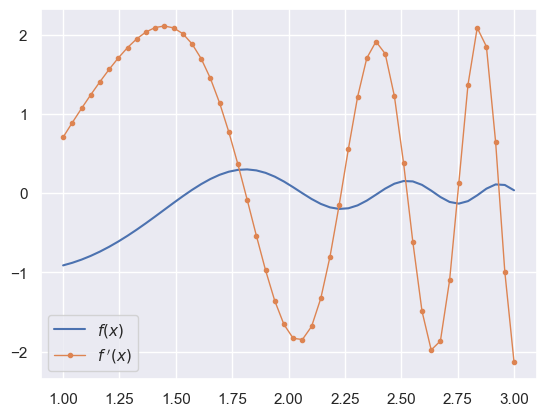
Derivatives of \(f(\mathbf{x})\) are very useful for optimization and can be calculated several ways. The first method is to work out the derivatives by hand and code them up, for example:
def f(x):
return np.cos(np.exp(x)) / x ** 2
def fp(x):
return -2 * np.cos(np.exp(x)) / x ** 3 - np.exp(x) * np.sin(np.exp(x)) / x ** 2
x = np.linspace(1, 3, 50)
plt.plot(x, f(x), label='$f(x)$')
plt.plot(x, fp(x), '.-', lw=1, label='$f^{~\prime}(x)$')
plt.legend()
plt.show()
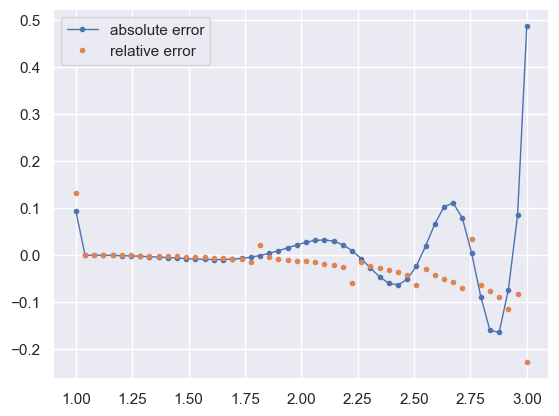
Derivatives can also be calculated numerically using finite difference equations such as:
For example, with np.gradient:
fp_numeric = np.gradient(f(x), x)
plt.plot(x, (fp_numeric - fp(x)), '.-', lw=1, label='absolute error')
plt.plot(x, (fp_numeric - fp(x)) / fp(x), '.', label='relative error')
plt.legend()
plt.show()
There is also a third hybrid approach that has proven very useful in machine learning, especially for training deep neural networks: automatic differentiation. This requires that a small set of primitive functions (sin, cos, exp, log, …) are handled analytically, and then composition of these primitives is handled by applying the rules of differentiation (chain rule, product rule, etc) directly to the code that evaluates f(x).
For example, using the autograd package:
from autograd import grad, elementwise_grad
import autograd.numpy as anp
and the same function \(f(x)\) we had before
def f_auto(x):
return anp.cos(anp.exp(x)) / x ** 2
fp_auto = elementwise_grad(f_auto)
In this case, the automatic derivates are identical to the exact results up to round-off errors (note the 1e-16 multiplier on the y axis):
plt.plot(x, fp_auto(x) - fp(x), '.-', lw=1)
plt.show()
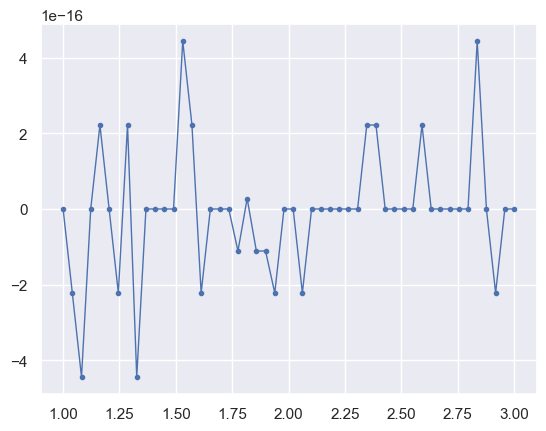
Note that automatic differentiation cannot perform miracles. For example, the following implementation of
cannot be evaluated at \(x = 0\), so neither can its automatic derivative:
def sinc(x):
return anp.sin(x) / x
sinc(0.)
np.float64(nan)
grad(sinc)(0.)
np.float64(nan)
EXERCISE: Modify the implementation of sinc above to cure both of these problems. Hint: grad can automatically differentiate through control flow structures (if, while, etc).
The simplest fix is to return 1 whenever \(x\) is zero:
def sinc(x):
return anp.sin(x) / x if x != 0 else 1.
assert sinc(0.) == 1
This gives the correct derivative but still generates a warning because \(x = 0\) is treated as an isolated point:
grad(sinc)(0.)
array(0.)
A better solution is to use a Taylor expansion for \(|x| \lt \epsilon\):
def sinc(x):
return anp.sin(x) / x if np.abs(x) > 0.001 else 1 - x ** 2 / 6
assert sinc(0.) == 1
assert grad(sinc)(0.) == 0
We will see automatic differentiation again soon in other contexts.
Optimization in Machine Learning#
Most ML algorithms involve some sort of optimization (although MCMC sampling is an important exception). For example, the K-means clustering algorithm minimizes
where \(c_j = 1\) if sample \(j\) is assigned to cluster \(i\) or otherwise \(c_j = 0\), and
is the mean of samples assigned to cluster \(i\).
Optimization is also useful in Bayesian inference. In particular, it allows us to locate the most probable point in the parameter space, known as the maximum a-posteriori (MAP) point estimate:
You can also locate the point that is most probable according to just your likelihood, known as the maximum likelihood (ML) point estimate:
Frequentists who do not believe in priors generally focuses on ML, but MAP is the fundamental point estimate in Bayesian inference. Note that the log above reduces round-off errors when the optimizer needs to explore a large dynamic range (as is often true) and the minus sign converts a maximum probability into a minimum function value.
Note that a point estimate is not very useful on its own since it provides no information on what range of \(\theta\) is consistent with the data, otherwise known as the parameter uncertainty! Point estimates are still useful, however, to provide a good starting point for MCMC chains or when followed by an exploration of the surrounding posterior to estimate uncertainties.
Variational inference is another important application of optimization, where it allows us to find the “closest” approximating PDF \(q(\theta; \lambda)\) to the true posterior PDF \(P(\theta\mid D)\) by optimizing with respect to variables \(\lambda\) that explore the approximating family \(q\):
Finally, training a neural network is essentially an optimization task, as we will shall see soon.
Optimization Methods#
To compare different methods, we will use the Rosenbrock function, which is smooth but sufficiently non-linear to be a good challenge:
Most implementations need a function that takes all components of \(\mathbf{x}\) in a single array argument:
def rosenbrock(x):
x0, x1 = x
return (1 - x0) ** 2 + 100.0 * (x1 - x0 ** 2) ** 2
Below is a helper function to demonstarate optimization with the Rosenbrock function called plot_rosenbrock:
def plot_rosenbrock(xrange=(-1.5, 1.5), yrange=(-0.5,1.5), ngrid=500,
shaded=True, path=None, all_calls=None, ax=None):
x_grid = np.linspace(*xrange, ngrid)
y_grid = np.linspace(*yrange, ngrid)
f = (1 - x_grid) ** 2 + 100.0 * (y_grid[:, np.newaxis] - x_grid ** 2) ** 2
if ax is None:
fig, ax = plt.subplots(figsize=(9,5))
if shaded:
ax.imshow(np.log10(f), origin='lower', extent=[*xrange, *yrange],
cmap='plasma', aspect='auto')
c = ax.contour(x_grid, y_grid, f, levels=[0.1, 1., 10., 100.],
colors='w', linewidths=1, linestyles='-')
ax.clabel(c, inline=1, fontsize=10, fmt='%.0g')
ax.axhline(1, c='gray', lw=1, ls='--')
ax.axvline(1, c='gray', lw=1, ls='--')
ax.set_xlabel('$x_0$')
ax.set_ylabel('$x_1$')
if all_calls is not None:
ax.scatter(*np.array(all_calls).T, lw=0, s=10, c='cyan')
if path is not None:
path = np.array(path)
ax.scatter(*path.T, lw=0, s=10, c='k')
ax.plot(*path.T, lw=1, c='k', alpha=0.3)
ax.scatter(*path[0], marker='x', s=250, c='b')
ax.set_xlim(*xrange)
ax.set_ylim(*yrange)
return xrange, yrange, ax
This function has a curved valley with a shallow minimum at \((x,y) = (1,1)\) and steeply rising sides:
plot_rosenbrock()
plt.show()
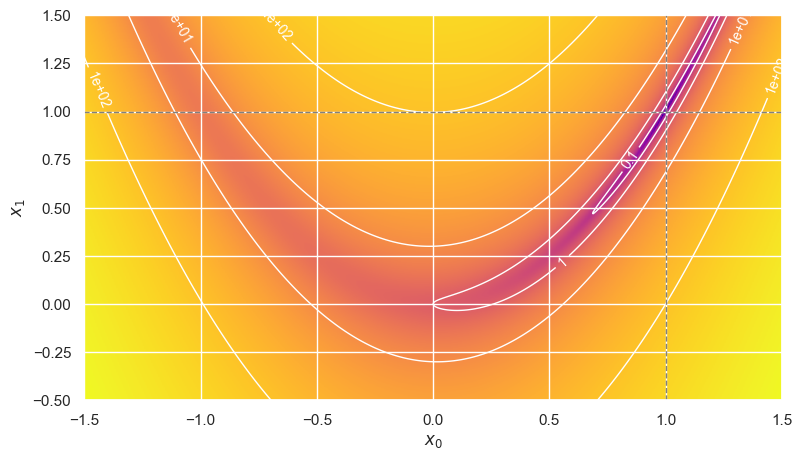
EXERCISE: Is the Rosenbrock function convex? In other words, does a straight line between any two points on its surface always lie above the surface?
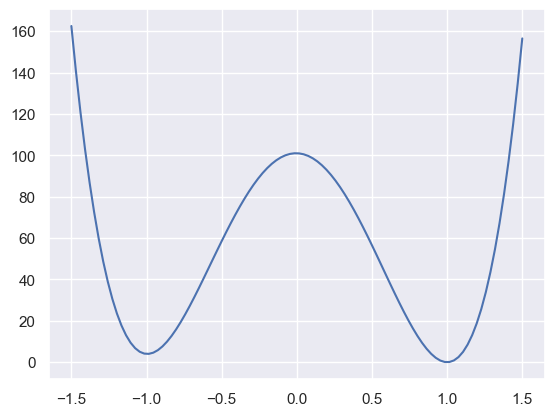
The Rosenbrock function is not convex. Take, for example, the line \(x_1 = 1\) shown above:
x0 = np.linspace(-1.5, 1.5, 100)
plt.plot(x0, rosenbrock([x0, 1.0]))
plt.show()
The scipy.optimize module implements a suite of standard general-purpose algorithms that are accessible via its minimize function. For example, to find the minimum of the Rosenbrock function starting from \((-1,0)\) and using the robust Nelder-Mead algorithm (aka downhill simplex method or amoeba method), which does not use derivatives:
opt = minimize(rosenbrock, [-1, 0], method='Nelder-Mead', tol=1e-4)
print(opt.message, opt.x)
Optimization terminated successfully. [1.00000935 1.00001571]
The tol (tolerance) parameter roughly corresponds to the desired accuracy in each coordinate.
Most methods accept an optional jac (for Jacobian) argument to pass a function that calculates partial derivatives along each coordinate. For our Rosenbrock example, we can construct a suitable function using automatic differentiation:
rosenbrock_grad = grad(rosenbrock)
Here is an example of optimizing using derivatives with the conjugate-gradient (CG) method:
opt = minimize(rosenbrock, [-1, 0], method='CG', jac=rosenbrock_grad, tol=1e-4)
print(opt.message, opt.x)
Optimization terminated successfully. [0.99999634 0.99999279]
A method using derivatives will generally require fewer calls to \(f(\mathbf{x})\) but might still be slower due to the additional partial derivative evaluations. Some (but not all) methods that use partial derivatives will estimate them numerically, with additional calls to \(f(\mathbf{x})\), if a jac function is not provided.
The function below uses wrappers to track and display the optimizer’s progress, and also displays the running time:
def optimize_rosenbrock(method, use_grad=False, x0=-1, y0=0, tol=1e-4):
all_calls = []
def rosenbrock_wrapped(x):
all_calls.append(x)
return rosenbrock(x)
path = [(x0,y0)]
def track(x):
path.append(x)
jac = rosenbrock_grad if use_grad else False
start = time.time()
opt = minimize(rosenbrock_wrapped, [x0, y0], method=method, jac=jac, tol=tol, callback=track)
stop = time.time()
assert opt.nfev == len(all_calls)
njev = opt.get('njev', 0)
print('Error is ({:+.2g},{:+.2g}) after {} iterations making {}+{} calls in {:.2f} ms.'
.format(*(opt.x - np.ones(2)), opt.nit, opt.nfev, njev, 1e3 * (stop - start)))
xrange, yrange, _ = plot_rosenbrock(path=path, all_calls=all_calls)
Black points show the progress after each iteration of the optimizer and cyan points show additional auxiliary calls to \(f(\mathbf{x})\):
optimize_rosenbrock(method='Nelder-Mead', use_grad=False)
Error is (+9.4e-06,+1.6e-05) after 83 iterations making 153+0 calls in 9.15 ms.
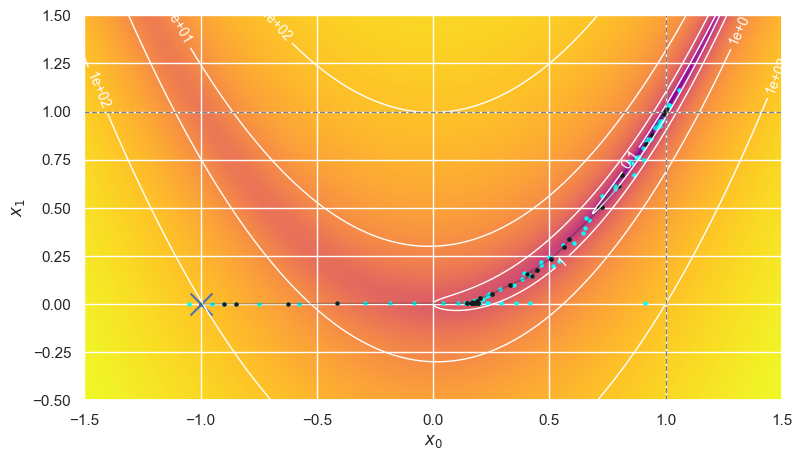
In this example, we found the true minimum with an error below \(10^{-4}\) in each coordinate (as requested) using about 150 calls to evaluate \(f(\mathbf{x})\), but an exhaustive grid search would have required more than \(10^{8}\) calls to achieve comparable accuracy!
The conjugate-gradient (CG) method uses gradient derivatives to always move downhill:
optimize_rosenbrock(method='CG', use_grad=True)
Error is (-3.7e-06,-7.2e-06) after 20 iterations making 43+43 calls in 10.42 ms.
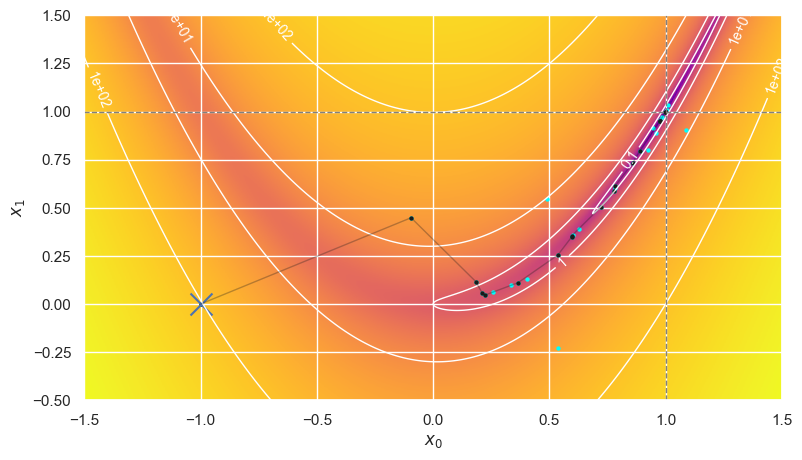
CG can follow essentially the same path using numerical estimates of the gradient derivatives, which requires more evaluations of \(f(\mathbf{x})\) but is still faster in this case:
optimize_rosenbrock(method='CG', use_grad=False)
Error is (-7.4e-06,-1.5e-05) after 20 iterations making 129+43 calls in 7.75 ms.
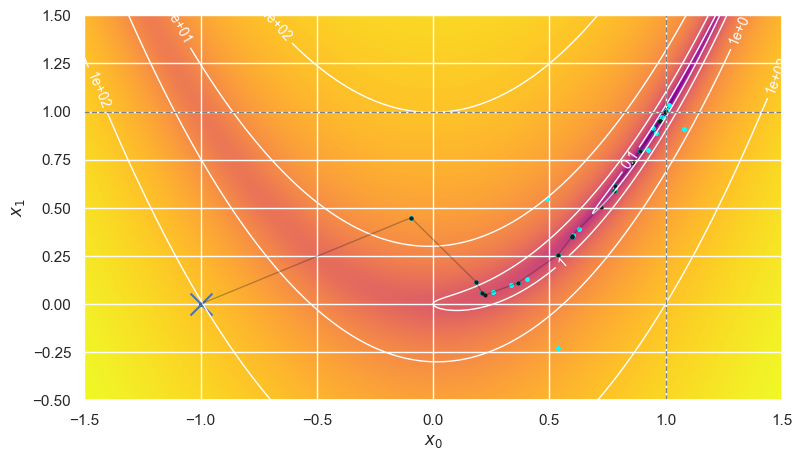
Newton’s CG method requires analytic derivatives and makes heavy use of them to measure and exploit the curvature of the local surface:
optimize_rosenbrock(method='Newton-CG', use_grad=True)
Error is (-1.2e-06,-2.3e-06) after 38 iterations making 51+129 calls in 23.60 ms.
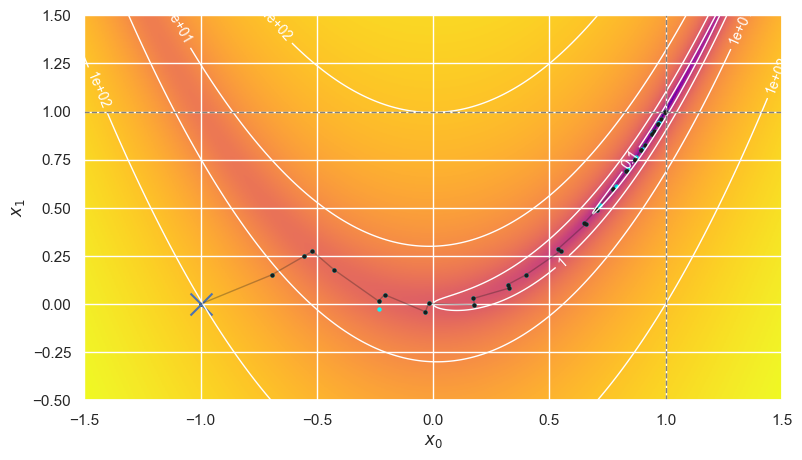
Powell’s method does not use derivatives but requires many auxiliary evaluations of \(f(\mathbf{x})\):
optimize_rosenbrock(method='Powell', use_grad=False)
Error is (-2.2e-16,-5.6e-16) after 15 iterations making 383+0 calls in 3.91 ms.
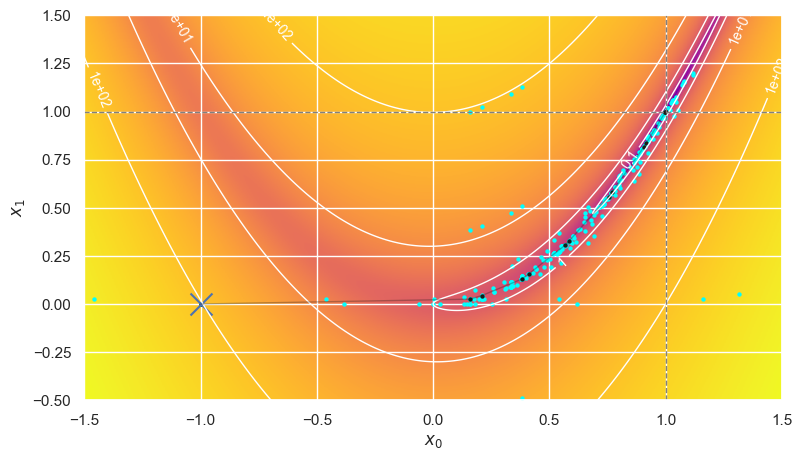
Finally, the BFGS method is a good all-around default choice, with or without derivatives:
optimize_rosenbrock(method='BFGS', use_grad=False)
Error is (-7.2e-06,-1.4e-05) after 25 iterations making 99+33 calls in 5.98 ms.
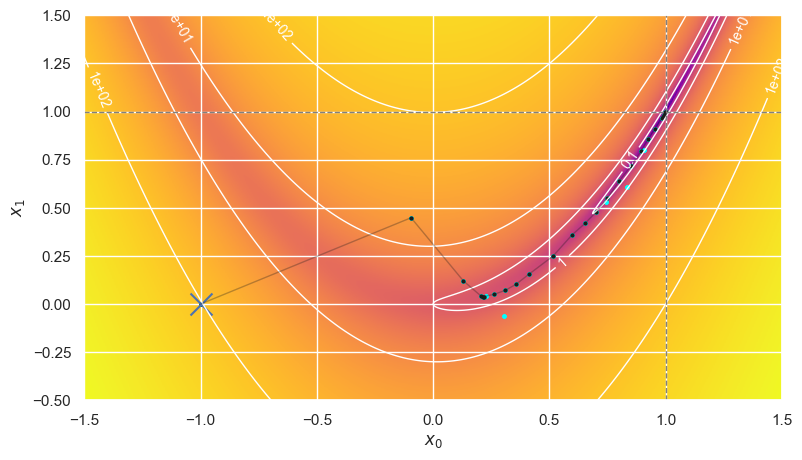
The choice of initial starting point can have a big effect on the optimization cost, as measured by the number of calls to evaluate \(f(\mathbf{x})\). For example, compare:
optimize_rosenbrock(method='BFGS', use_grad=False, x0=1.15, y0=0.5)
Error is (-5.7e-06,-1.2e-05) after 15 iterations making 54+18 calls in 3.90 ms.
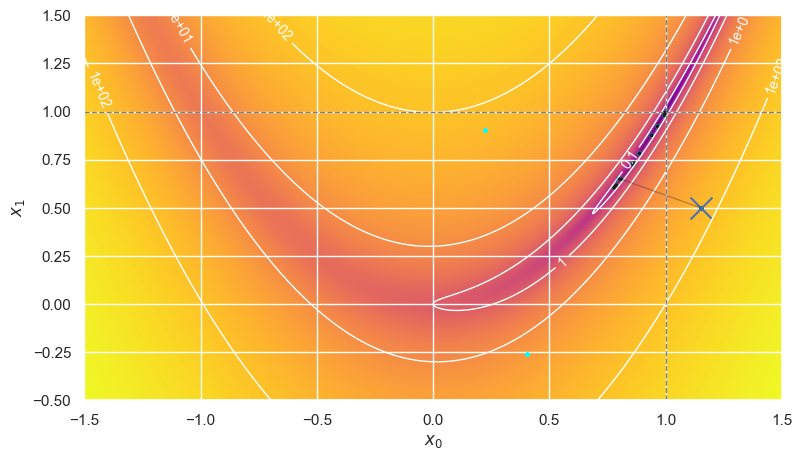
optimize_rosenbrock(method='BFGS', use_grad=False, x0=1.20, y0=0.5)
Error is (-4.5e-06,-8.9e-06) after 34 iterations making 123+41 calls in 7.77 ms.
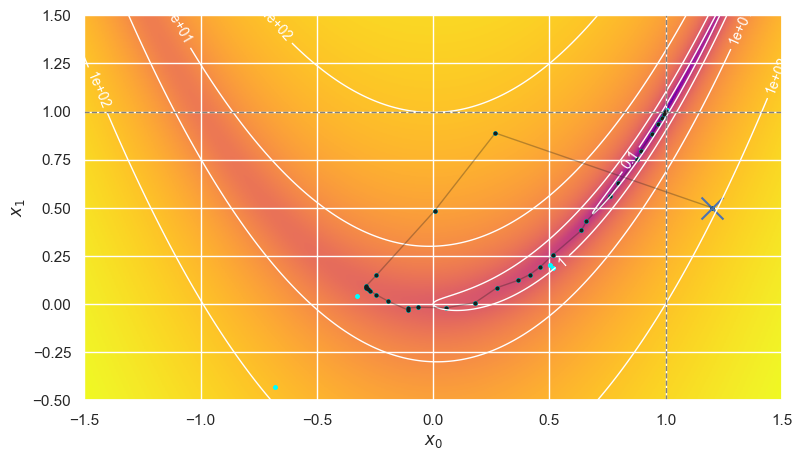
EXERCISE: Predict which initial starting points would require the most calls to evaluate \(f(\mathbf{x})\) for the Rosenbrock function? Does your answer depend on the optimization method?
The cost can be very sensitive to the initial conditions in ways that are difficult to predict. Different methods will have different sensitivities but, generally, the slower more robust methods should be less sensitive with more predictable costs.
The function below maps the cost as a function of the starting point:
def cost_map(method, tol=1e-4, ngrid=50):
fig, ax = plt.subplots(figsize=(9,5))
xrange, yrange, _ = plot_rosenbrock(shaded=False, ax=ax)
x0_vec = np.linspace(*xrange, ngrid)
y0_vec = np.linspace(*yrange, ngrid)
cost = np.empty((ngrid, ngrid))
for i, x0 in enumerate(x0_vec):
for j, y0 in enumerate(y0_vec):
opt = minimize(rosenbrock, [x0, y0], method=method, tol=tol)
cost[j, i] = opt.nfev
im = ax.imshow(cost, origin='lower', extent=[*xrange, *yrange],
interpolation='none', cmap='magma', aspect='auto', vmin=0, vmax=250)
fig.colorbar(im, ax=ax, label='Number of calls')
plt.show()
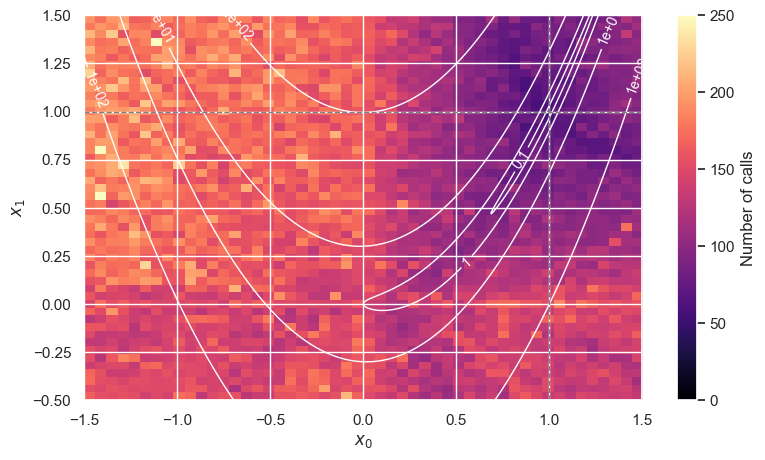
The BFGS “racehorse” exhibits some surprising discontinuities in its cost function:
cost_map('BFGS')
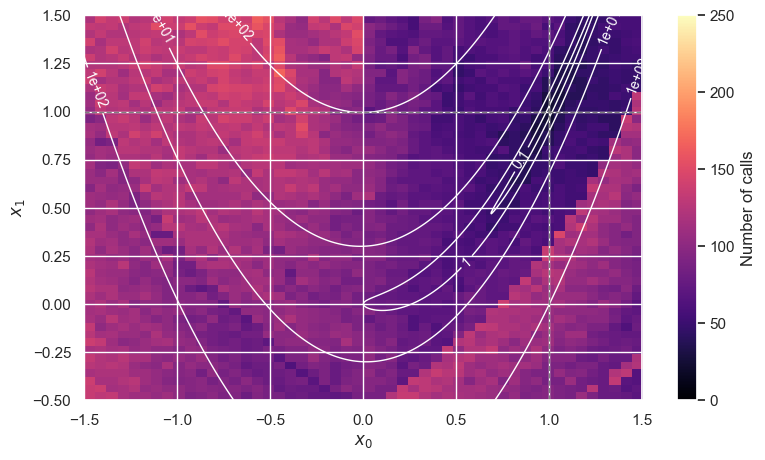
The Nelder-Mead “ox”, in contrast, is more expensive overall (both plots use the same color scale), but has a smoother cost function (but there are still some isolated “hot spots”):
cost_map('Nelder-Mead')
When the function you are optimizing is derived from a likelihood (which includes a chi-squared likelihood for binned data), there are some other optimization packages that you might find useful:
Stochastic Optimization#
In machine-learning applications, the function being optimized often involves an inner loop over data samples. For example, in Bayesian inference, this enters via the likelihood,
where the \(x_i\) are the individual data samples. With a large number of samples, this iteration can be prohibitively slow, but stochastic optimization provides a neat solution.
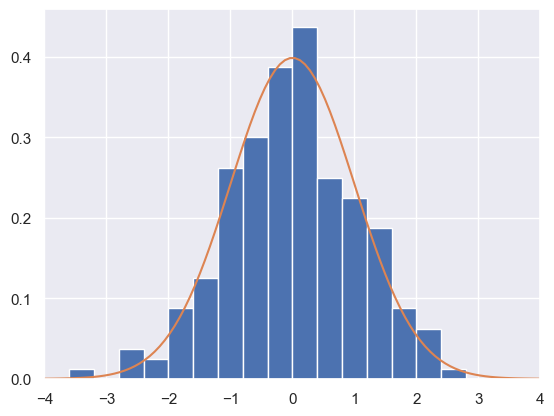
For example, generate some data from a Gaussian likelihood:
D = scipy.stats.norm.rvs(loc=0, scale=1, size=200, random_state=123)
x = np.linspace(-4, +4, 100)
plt.hist(D, range=(x[0], x[-1]), bins=20, density=True)
plt.plot(x, scipy.stats.norm.pdf(x,loc=0,scale=1))
plt.xlim(x[0], x[-1]);
The corresponding negative-log-likelihood (NLL) function of the loc and scale parameters is then (we write it out explicitly using autograd numpy calls so we can perform automatic differentiation later):
def NLL(theta, D):
mu, sigma = theta
return anp.sum(0.5 * (D - mu) ** 2 / sigma ** 2 + 0.5 * anp.log(2 * anp.pi) + anp.log(sigma))
Add (un-normalized) flat priors on \(\mu\) and \(\log\sigma\) (these are the “natural” un-informative priors for additive and multiplicative constants, respectively):
def NLP(theta):
mu, sigma = theta
return -anp.log(sigma) if sigma > 0 else -anp.inf
def NLpost(theta, D):
return NLL(theta, D) + NLP(theta)
The function we want optimize is then the negative-log-posterior:
Here is a helper function called plot_posterior:
def plot_posterior(D, mu_range=(-0.5,0.5), sigma_range=(0.7,1.5), ngrid=100,
path=None, VI=None, MC=None):
"""Plot a posterior with optional algorithm results superimposed.
Assumes a Gaussian likelihood with parameters (mu, sigma) and flat
priors in mu and t=log(sigma).
Parameters
----------
D : array
Dataset to use for the true posterior.
mu_range : tuple
Limits (lo, hi) of mu to plot
sigma_range : tuple
Limits (lo, hi) of sigma to plot.
ngrid : int
Number of grid points to use for tabulating the true posterior.
path : array or None
An array of shape (npath, 2) giving the path used to find the MAP.
VI : array or None
Values of the variational parameters (s0, s1, s2, s3) to use to
display the closest variational approximation.
MC : tuple
Tuple (mu, sigma) of 1D arrays with the same length, consisting of
MCMC samples of the posterior to display.
"""
# Create a grid covering the (mu, sigma) parameter space.
mu = np.linspace(*mu_range, ngrid)
sigma = np.linspace(*sigma_range, ngrid)
sigma_ = sigma[:, np.newaxis]
log_sigma_ = np.log(sigma_)
# Calculate the true -log(posterior) up to a constant.
NLL = np.sum(0.5 * (D[:, np.newaxis, np.newaxis] - mu) ** 2 / sigma_** 2 +
log_sigma_, axis=0)
# Apply uniform priors on mu and log(sigma)
NLP = NLL - log_sigma_
NLP -= np.min(NLP)
if VI is not None:
s0, s1, s2, s3 = VI
# Calculate the VI approximate -log(posterior) up to a constant.
NLQ = (0.5 * (mu - s0) ** 2 / np.exp(s1) ** 2 +
0.5 * (log_sigma_ - s2) ** 2 / np.exp(s3) ** 2)
NLQ -= np.min(NLQ)
fig = plt.figure(figsize=(8, 6))
plt.imshow(NLP, origin='lower', extent=[*mu_range, *sigma_range],
cmap='viridis_r', aspect='auto', vmax=16)
c = plt.contour(mu, sigma, NLP, levels=[1, 2, 4, 8],
colors='w', linewidths=1, linestyles='-')
plt.clabel(c, inline=1, fontsize=10, fmt='%.0g')
plt.plot([], [], 'w-', label='true posterior')
if path is not None:
plt.scatter(*np.array(path).T, lw=0, s=15, c='r')
plt.plot(*np.array(path).T, lw=0.5, c='r', label='MAP optimization')
plt.scatter(*path[0], marker='x', s=250, c='r')
if VI is not None:
plt.contour(mu, sigma, NLQ, levels=[1, 2, 4, 8],
colors='r', linewidths=2, linestyles='--')
plt.plot([], [], 'r--', label='VI approximation')
if MC is not None:
mu, sigma = MC
plt.scatter(mu, sigma, s=15, alpha=0.8, zorder=10, lw=0, c='r',
label='MC samples')
l = plt.legend(ncol=3, loc='upper center')
plt.setp(l.get_texts(), color='w', fontsize='x-large')
plt.axhline(1, c='gray', lw=1, ls='--')
plt.axvline(0, c='gray', lw=1, ls='--')
plt.grid(False)
plt.xlabel('Offset parameter $\mu$')
plt.ylabel('Scale parameter $\sigma$')
plt.xlim(*mu_range)
plt.ylim(*sigma_range)
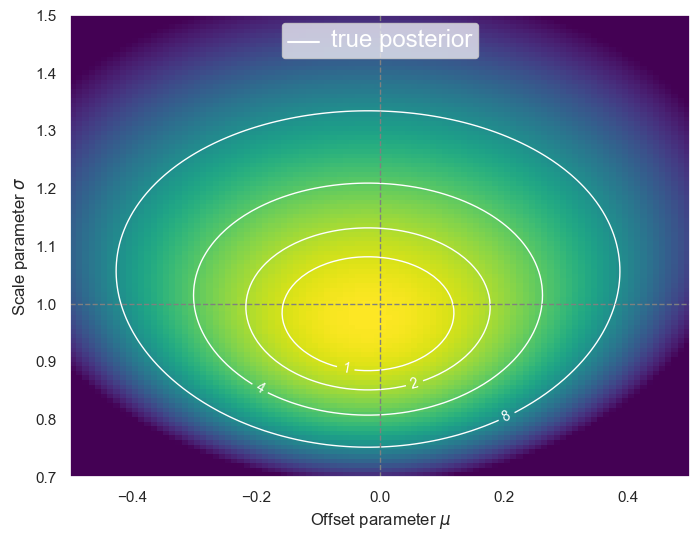
plot_posterior(D)
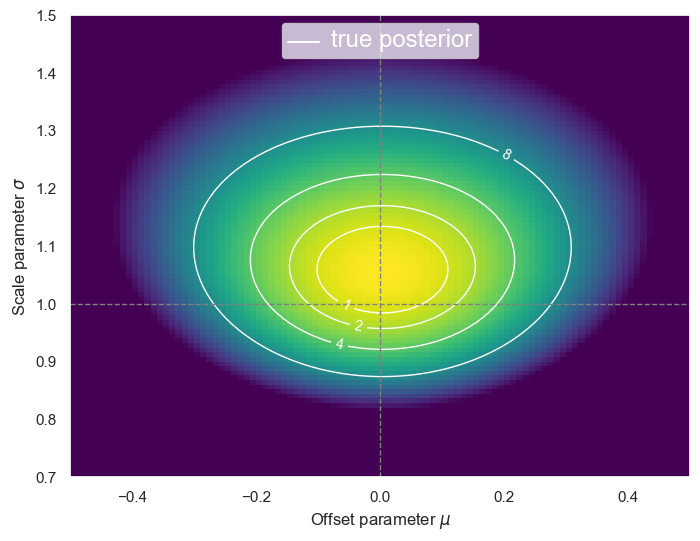
DISCUSS: Why is \(f(\theta)\) not centered at the true value \((\mu, \sigma) = (0, 1)\)?
There are two reasons:
Statistical fluctuations in the randomly generated data will generally offset the maximum likelihood contours. The expected size of this shift is referred to as the statistical uncertainty.
The priors favor a lower value of \(\sigma\), which pulls these contours down. The size of this shift will be negligible for an informative experiment, and significant when there is insufficient data.
DISCUSS: How do you expect the plot above to change if only half of the data is used? How would using the first or second half change the plot?
Using half of the data will increase the statistical uncertainty, resulting in larger contours. Independent subsets of the data will have uncorrelated shifts due to the statistical uncertainty.
plot_posterior(D[:100]);
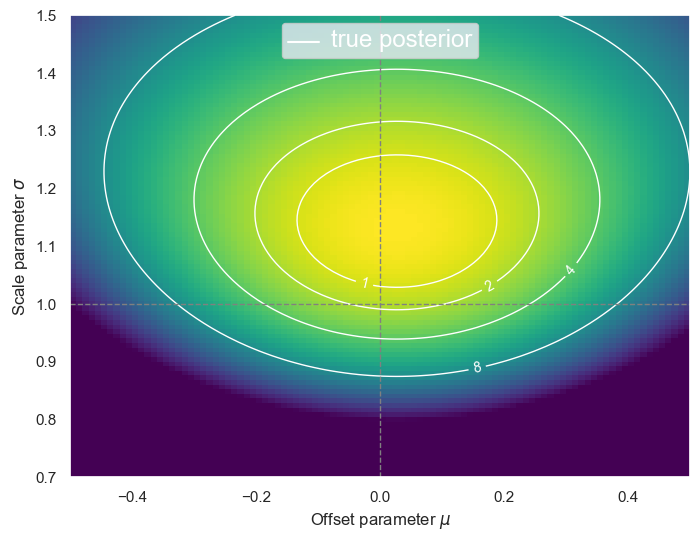
plot_posterior(D[100:]);
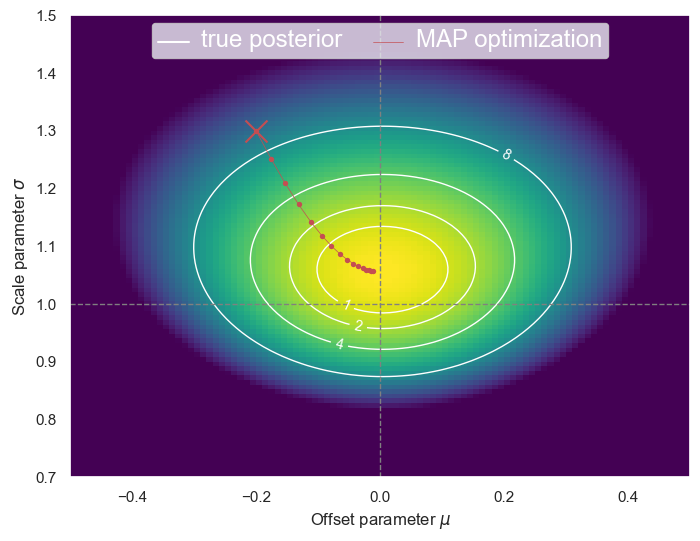
We will optimize this function using a simple gradient descent with a fixed learning rate \(\eta\):
where \(N\) is the number of samples in \(D\).
Use automatic differentiation to calculate the gradient of \(f(\theta)\) with respect to the components of \(\theta\) (\(\mu\) and \(\sigma\)):
NLpost_grad = grad(NLpost)
def step(theta, D, eta):
return theta - eta * NLpost_grad(theta, D) / len(D)
def GradientDescent(mu0, sigma0, eta, n_steps):
path = [np.array([mu0, sigma0])]
for i in range(n_steps):
path.append(step(path[-1], D, eta))
return path
The resulting path rolls “downhill”, just as we would expect. Note that a constant learning rate does not translate to a constant step size. (Why?)
plot_posterior(D, path=GradientDescent(mu0=-0.2, sigma0=1.3, eta=0.2, n_steps=15))
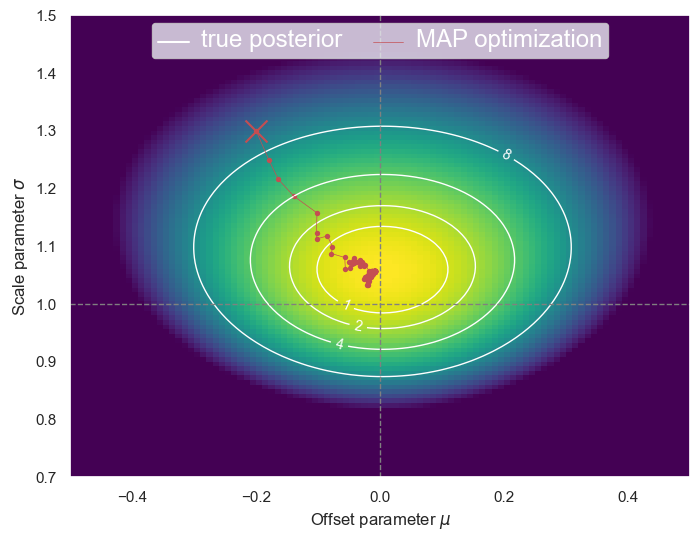
The stochastic gradient method uses a random subset of the data, called a minibatch, during each iteration. Only small changes to StochasticGradient above are required to implement this scheme (and no changes are needed to step):
Add a
seedparameter for reproducible random subsets.Specify the minibatch size
n_minibatchand use np.random.choice to select it during each iteration.Reduce the learning rate after each iteration by
eta_factor.
def StochasticGradientDescent(mu0, sigma0, eta, n_minibatch, eta_factor=0.95, seed=123, n_steps=15):
gen = np.random.RandomState(seed=seed)
path = [np.array([mu0, sigma0])]
for i in range(n_steps):
minibatch = gen.choice(D, n_minibatch, replace=False)
path.append(step(path[-1], minibatch, eta))
eta *= eta_factor
return path
Using half of the data on each iteration (n_minibatch=100) means that the gradient is calculated from a different surface each time, with larger contours and random shifts. We have effectively added some noise to the gradient, but it still converges reasonably well:
plot_posterior(D, path=StochasticGradientDescent(
mu0=-0.2, sigma0=1.3, eta=0.2, n_minibatch=100, n_steps=100))
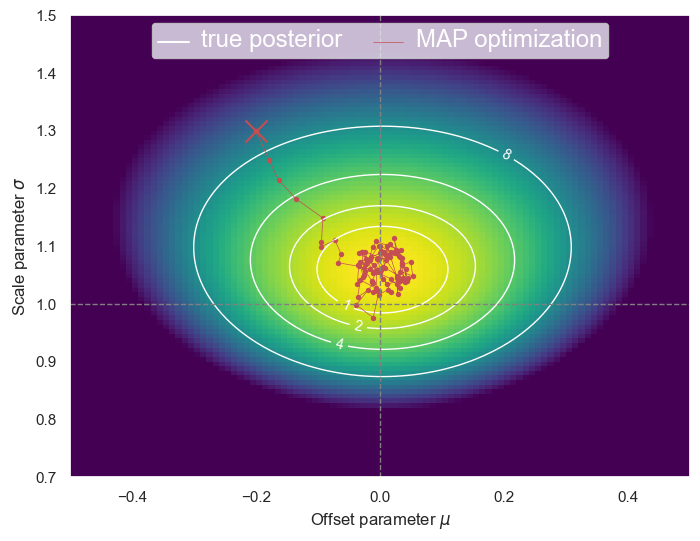
Note that the learning-rate decay is essential to prevent the optimizer wandering aimlessly once it gets close to the minimum:
plot_posterior(D, path=StochasticGradientDescent(
mu0=-0.2, sigma0=1.3, eta=0.2, eta_factor=1, n_minibatch=100, n_steps=100))
Remarkably, stochastic gradient descent (SGD) works with even smaller minibatches, with some careful tuning of the hyperparameters, although it might converge to a slightly different minimum. For example:
plot_posterior(D, path=StochasticGradientDescent(
mu0=-0.2, sigma0=1.3, eta=0.15, eta_factor=0.97, n_minibatch=20, n_steps=75))
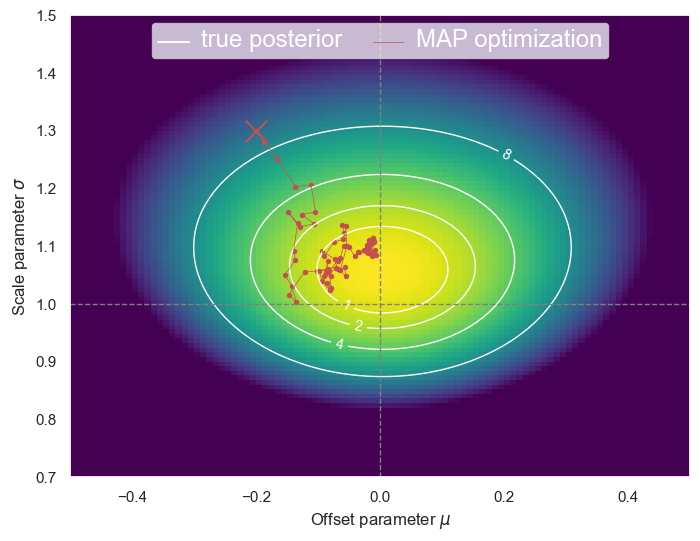
Comparing this example with our GradientDescent above, we find that the number of steps has increased 5x while the amount of data used during each iteration has decreased 10x, so roughly a net factor of 2 improvement in overall performance.
SGD has been used very successfully in training deep neural networks, where it solves two problems:
Deep learning requires massive training datasets which are then slow to optimize, so any gains in performance are welcome.
The noise introduced by SGD helps prevent “over-learning” of the training data and improves the resulting ability to generalize to data outside the training set. We will revisit this theme soon.
Acknowledgments#
Initial version: Mark Neubauer
© Copyright 2025